


An Oracle Database consists of at least one database instance and one database. The database instance handles memory and processes. The database consists of physical files called data files, and can be a non- container database or a multitenant container database. An Oracle Database also uses several database system files during its operation.
A single-instance database architecture consists of one database instance and one database. A one-to-one relationship exists between the database and the database instance. Multiple single-instance databases can be installed on the same server machine. There are separate database instances for each database. This configuration is useful to run different versions of Oracle Database on the same machine.
An Oracle Real Application Clusters (Oracle RAC) database architecture consists of multiple instances that run on separate server machines. All of them share the same database. The cluster of server machines appear as a single server on one end, and end users and applications on the other end. This configuration is designed for high availability, scalability, and high-end performance.
The listener is a database server process. It receives client requests, establishes a connection to the database
instance, and then hands over the client connection to the server process. The listener can run locally on the database server or run remotely. Typical Oracle RAC environments are run remotely.

A database instance contains a set of Oracle Database background processes and memory structures. The main memory structures are the System Global Area (SGA) and the Program Global Areas (PGAs). The background processes operate on the stored data (data files) in the database and use the memory structures to do their work. A database instance exists only in memory.
Oracle Database
also creates server processes to handle the connections to the database
on behalf of client programs,
and to perform the work for the client programs;
for example, parsing and running SQL statements, and retrieving and returning results to the client programs.
These types of server processes
are also referred
to as foreground processes.

The System Global Area (SGA) is the memory area that contains data and control information for one Oracle Database instance. All server and background processes share the SGA. When you start a database instance, the amount of memory allocated for the SGA is displayed. The SGA includes the following data structures:
·
Shared pool: Caches various constructs that can be shared among users; for example, the shared pool stores parsed SQL, PL/SQL code, system parameters, and data dictionary information. The shared pool is involved in almost every operation that occurs in the database.
For example, if a user executes a SQL statement, then Oracle Database
accesses the shared pool.
·
Flashback buffer: Is an optional component
in the SGA. When Flashback
Database is enabled,
the background process called Recovery
Writer Process (RVWR) is started.
RVWR periodically copies modified blocks from the buffer cache to the flashback buffer, and sequentially writes Flashback Database
data from the flashback buffer to the Flashback Database
logs, which are circularly reused.
·
Database buffer cache: Is the memory area that stores copies of data blocks read from data files. A buffer is a main memory address in which the buffer manager temporarily caches a currently
or recently used data block. All users concurrently connected
to a database instance share access to the buffer cache.
·
Database Smart Flash cache: Is an optional memory extension of the database buffer cache for databases
running on Solaris or Oracle Linux. It provides a level 2 cache for database blocks. It can improve response
time and overall throughput for both read-intensive online transaction processing (OLTP) workloads and ad-hoc queries
and bulk data modifications in a data warehouse (DW) environment. Database Smart Flash Cache resides on one or more flash disk devices,
which are solid state storage
devices that use flash memory. Database Smart Flash Cache is typically
more economical than additional main memory, and is an order of magnitude faster than disk drives.
·
Redo log buffer: Is a circular buffer in the SGA that holds information about changes made to the database. This information is stored in redo entries. Redo entries contain the information necessary
to reconstruct (or redo) changes
that are made to the database by data manipulation language (DML), data definition language
(DDL), or internal
operations. Redo entries
are used for database recovery
if necessary.
·
Large pool: Is an optional memory area intended for memory allocations that are larger than is appropriate for the shared pool. The large pool can provide large memory allocations for the User Global Area (UGA) for the shared server and the Oracle XA interface
(used where transactions interact with multiple
databases), message buffers used in the parallel execution of statements, buffers for Recovery
Manager (RMAN) I/O slaves, and deferred inserts.
·
In-Memory Area: Is an optional component
that enables objects (tables, partitions, and other types) to be stored in memory in a new format known as the columnar format. This format enables scans, joins, and aggregates to perform much faster than the traditional on-disk format, thus providing fast reporting and DML performance for both OLTP and DW environments. This feature is particularly useful for analytic
applications that operate on a few columns returning many rows rather than for OLTP, which operates on a few rows returning
many columns.
·
Memoptimize Pool: Is an optional component
that provides high performance and scalability for key- based queries. The Memoptimize Pool contains two parts, the memoptimize buffer area and the hash index. Fast lookup uses the hash index structure
in the memoptimize pool providing
fast access to the blocks
of a given table (enabled
for MEMOPTIMIZE FOR READ) permanently pinned in the buffer cache to avoid disk I/O. The buffers in the memoptimize pool are completely
separate from the database buffer cache. The hash index is created when the Memoptimized Rowstore
is configured, and is maintained
automatically by Oracle Database.
· Shared I/O pool (SecureFiles): Is used for large I/O operations on SecureFile Large Objects (LOBs).
LOBs are a set of data types that are designed to hold large amounts
of data. SecureFile is an LOB storage parameter that allows deduplication, encryption,
and compression.
·
Streams pool: Is used by Oracle Streams, Data Pump, and GoldenGate integrated capture and apply processes. The Streams pool stores buffered queue messages,
and it provides memory for Oracle Streams capture processes
and apply processes.
Unless you specifically configure it, the size of the Streams
pool starts at zero. The pool size grows dynamically as needed when Oracle Streams is used.
·
Java pool: Is used for all session-specific Java code and data in the Java Virtual Machine (JVM). Java pool memory is used in different
ways, depending on the mode in which Oracle Database is running.
·
Fixed SGA: Is an internal housekeeping area containing general information about the state of the database and database instance,
and information communicated between processes.

The Program Global Area (PGA) is a non-shared memory region that contains data and control information exclusively for use by server and background processes.
Oracle Database creates server processes
to handle connections to the database
on behalf of client programs.
In a dedicated server environment, one PGA gets created for each server and background
process that is started. Each PGA consists
of stack space, hash area, bitmap merge area and a User Global Area (UGA). A PGA is deallocated when the associated
server or background process using it is terminated.
·
In a shared server environment, multiple client users share the server process. The UGA is moved into the large pool, leaving the PGA with only stack space, hash area, and bitmap merge area.
·
In a dedicated server session, the PGA consists
of the following components:
· SQL work areas: The sort area is used by functions
that order data, such as ORDER BY and GROUP BY.
· Session memory: This user session data storage area is allocated for session variables,
such as logon information, and other information required by a database session.
The OLAP pool manages OLAP data pages, which are equivalent to data blocks.
· Private SQL area: This area holds information about a parsed SQL statement
and other session-
specific information for processing. When a server process executes SQL or PL/SQL code, the process uses the private SQL area to store bind variable values, query execution
state information, and query execution
work areas. Multiple private SQL areas in the same or different
sessions can point to a single execution
plan in the SGA. The persistent area contains bind variable values.
The run-time area contains query execution
state information. A cursor is a name or handle to a specific area in the private SQL area. You can think of a cursor as a pointer on the client side and as a state on the server side. Because cursors
are closely associated with private SQL areas, the terms are sometimes used interchangeably.
· Stack space: Stack space is memory allocated to hold session variables and arrays.
· Hash area: This area is used to perform hash joins of tables.
· Bitmap merge area: This area is used to merge data retrieved from scans of multiple bitmap
indexes.
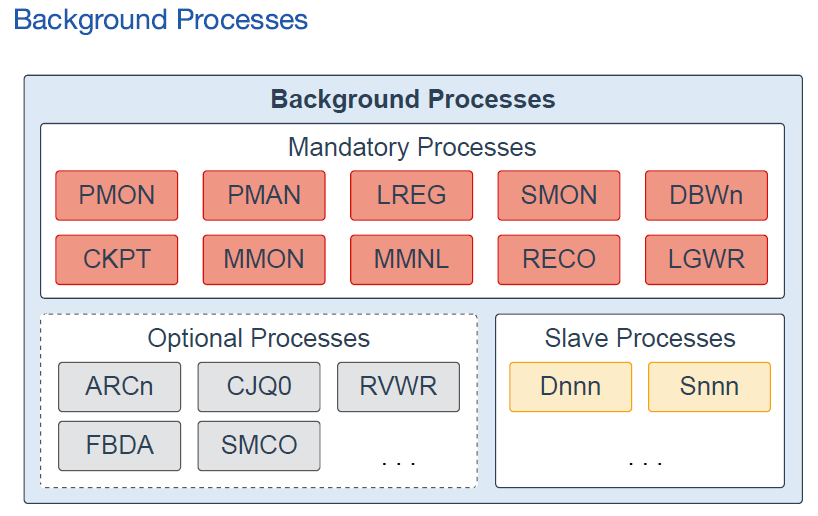
Background processes are part of the database instance and perform maintenance tasks required to operate the database and to maximize performance for multiple users. Each background process performs a unique task, but works with the other processes. Oracle Database creates background processes automatically when you start a database instance. The background processes that are present depend on the features that are being used in the database. When you start a database instance, mandatory background processes automatically start. You can start optional background processes later as required.
Mandatory background
processes are present
in all typical database configurations. These processes run by default in a read/write database instance started with a minimally configured
initialization parameter file. A read- only database instance disables
some of these processes. Mandatory
background processes include the Process Monitor Process (PMON), Process
Manager Process (PMAN), Listener Registration Process (LREG), System Monitor Process (SMON), Database Writer Process (DBWn),
Checkpoint Process (CKPT),
Manageability Monitor Process (MMON), Manageability Monitor Lite Process (MMNL), Recoverer
Process (RECO), and Log Writer Process (LGWR).
Most optional background processes are specific to tasks or features. Some common optional processes include Archiver Processes (ARCn), Job Queue Coordinator Process (CJQ0), Recovery Writer Process (RVWR), Flashback Data Archive Process (FBDA), and Space Management Coordinator Process (SMCO).
Slave processes are background
processes that perform work on behalf of other processes;
for example, the Dispatcher Process
(Dnnn) and Shared Server Process (Snnn).

The shared pool is a component
of the System Global Area (SGA) and is responsible for caching various types of program data. For example,
the shared pool stores parsed SQL, PL/SQL code, system parameters, and data dictionary information. The shared pool is involved in almost every operation that occurs in the database.
For example, if a user executes a SQL statement, then Oracle Database
accesses the shared pool.
The shared pool is divided into several
subcomponents:
Library
cache: Is a shared pool memory structure that stores executable
SQL and PL/SQL code. This cache contains
the shared SQL and PL/SQL areas and control structures, such as locks and library
cache handles. When a SQL statement is executed, the database attempts
to reuse previously executed code. If a parsed representation of a SQL statement exists in the library cache and can be shared, the database
reuses the code. This action is known as a soft parse or a library cache hit. Otherwise, the database must build a new executable version of the application code, which is known as a hard parse or a library
cache miss.
Reserved pool: Is a memory area in the shared pool that Oracle Database can use to allocate large contiguous chunks of memory.
The database allocates
memory from the shared pool in chunks. Chunking allows
large objects (over 5 KB) to be loaded into the cache without requiring
a single contiguous area. In this way, the database reduces the possibility of running out of contiguous memory because of fragmentation.
Data dictionary cache: Stores information about database objects (that is, dictionary data). This cache is also known as the row cache because it holds data as rows instead of buffers.
Server result cache: Is a memory pool within the shared pool and holds result sets. The server result cache contains the SQL query result cache and PL/SQL function result cache, which share the same infrastructure. The SQL query result cache stores the results of queries and query fragments.
Most applications benefit from this performance improvement. The PL/SQL function
result cache stores function result sets. Good candidates for result caching are frequently
invoked functions that depend on relatively static data.
Other components: Include enqueues, latches, Information Lifecycle Management (ILM) bitmap tables, Active Session History (ASH) buffers, and other minor memory structures. Enqueues are shared memory structures (locks) that serialize access to database resources. They can be associated with a session or transaction. Examples are: Controlfile Transaction, Datafile, Instance Recovery, Media Recovery, Transaction Recovery, Job Queue, and so on. Latches are used as a low-level serialization control mechanism used to protect shared data structures in the SGA from simultaneous access. Examples are row cache objects, library cache pin, and log file parallel write.

The large pool is an optional
memory area that database administrator's can configure to provide large memory allocations for the following:
·
User Global
Area (UGA): Session memory for the shared server and the Oracle
XA interface (used where transactions interact with multiple
databases)
·
I/O Buffer Area: I/O server processes,
message buffers used in parallel
query operations, buffers for Recovery
Manager (RMAN) I/O slaves, and advanced queuing memory table storage
·
Deferred Inserts Pool: The fast ingest feature enables high-frequency, single-row
data inserts into database for tables defined
as MEMOPTIMIZE FOR WRITE. The inserts
by fast ingest are also known as deferred inserts.
They are initially
buffered in the large pool and later written to disk asynchronously by the Space Management Coordinator (SMCO) and Wxxx slave background
processes after 1MB worth of writes per session per object or after 60 seconds. Any data buffered
in this pool, even committed, cannot be read by any session, including
the writer, until the SMCO background process
sweeps.
The pool is initialized in the large pool at the first inserted row of a memoptimized table. 2G is allocated from the large pool when there is enough space. If there is not enough space in the large pool, an ORA- 4031 is internally discovered
and automatically cleared.
The allocation is retried with half the requested size. If there is still not enough space in the large pool, the allocation is retried with 512M and 256M after which the feature is disabled until the instance
is restarted. Once the pool is initialized, the size remains static. It cannot grow or shrink.
·
Free memory
The large pool is different from reserved space in the shared pool, which uses the same Least Recently
Used (LRU) list as other memory allocated
from the shared pool. The large pool does not have an LRU list. Pieces of memory are allocated and cannot be freed until they are done being used.
A request from a user is a single API call that is part of the user's SQL statement.
In a dedicated server environment, one server process handles requests
for a single client process.
Each server process uses system resources, including CPU cycles and memory. In a shared server environment, the following actions occur:
1.
A client application sends a request to the database instance,
and that request is received
by the dispatcher.
2. The dispatcher places the request
on the request queue in the large pool.
3.
The request is picked up by the next available shared server process. The shared server processes
check the common request queue for new requests, picking up new
requests on a first-in-first-out basis. One
shared server process
picks up one request in the queue.
4.
The shared server process makes all the necessary
calls to the database to complete the request. First, the shared server process accesses the library cache in the shared pool to verify the requested
items; for example,
it checks whether the table exists, whether the user has the correct privileges, and so on. Next, the shared server process accesses the buffer cache to retrieve the data. If the data is not there, the shared server process accesses
the disk. A different shared server process can handle each database
call. Therefore, requests to parse a query, fetch the first row, fetch the next row, and close the result set may each be processed by a different
shared server process. Because a different shared server process may handle each database
call, the User Global Area (UGA) must be a Shared Memory area, as the UGA contains information about each client session. Or reversed, the UGA contains
information about each client session and must be available
to all shared server processes
because any shared server process
may handle any session's database
call.
5.
After the request is completed, a shared server process places the response
on the calling dispatcher's response
queue in the large pool. Each dispatcher has its own response queue.
6. The response queue sends the response to the dispatcher.
7.
The dispatcher returns the completed request
to the appropriate client application.

Relevant links from Oracle:
Oracle Database 12c: INTERACTIVE QUICK REFERENCE